Deep Q Networks for exploration of an autonomous agent:
In this project, an agent has to start from scratch in a previously unknown UnityML Enviornment and learn to navigate the enviornment by collecting the maximum amount of reward(yellow bananas) and avoid bad reward(blue bananas). A reward of +1 is provided for collecting a yellow banana, and a reward of -1 is provided for collecting a blue banana. The agent previously does not know the rules of this game and solely learns from interactions and reward feedback mechanism. The state space constitutes of 37 dimensions including agent's velocity and ray-based perception vector of objects around agent's forward direction. Given this information, the agent has to learn how to best select actions. Four discrete actions are available, corresponding to:
0 - move forward.
1 - move backward.
2 - turn left.
3 - turn right.
Algorithm Implementation Details:
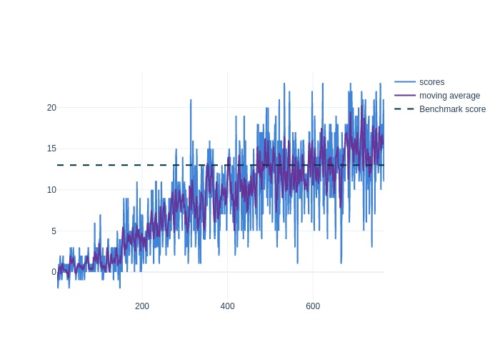
DQN Algorithm with Replay Buffer was used to solve this problem:
Results:
Deep Deterministic Policy Gradients for Continuous Control of 2-DOF Manipulator (Single Agent):
In this project, a double-jointed arm can move to target locations. A reward of +0.1 is provided for each step that the agent's hand is in the goal location. Thus, the goal of your agent is to maintain its position at the target location for as many time steps as possible.
The observation space consists of 33 variables corresponding to position, rotation, velocity, and angular velocities of the arm. Each action is a vector with four numbers, corresponding to torque applicable to two joints. Every entry in the action vector should be a number between -1 and 1.
Algorithm Implementation Details:
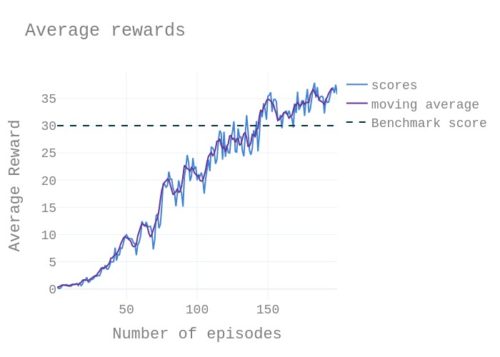
DDPG algorithm was used to solve this problem.
Results:
Deep Deterministic Policy Gradients for Multi-Agent Tennis Game (Multi-Agent):
In this project, two agents control rackets to bounce a ball over a net. If an agent hits the ball over the net, it receives a reward of +0.1. If an agent lets a ball hit the ground or hits the ball out of bounds, it receives a reward of -0.01. Thus, the goal of each agent is to keep the ball in play.
The observation space consists of 8 variables corresponding to the position and velocity of the ball and racket. Each agent receives its own, local observation. Two continuous actions are available, corresponding to movement toward (or away from) the net, and jumping.
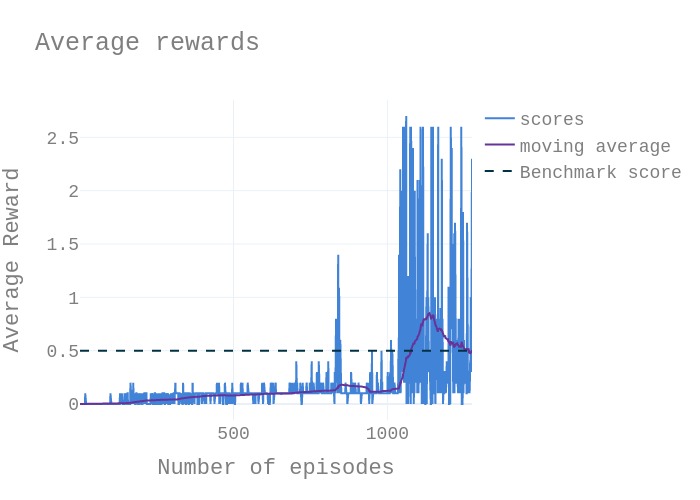
The task is episodic, and in order to solve the environment, your agents must get an average score of +0.5 (over 100 consecutive episodes, after taking the maximum over both agents). Specifically,
After each episode, we add up the rewards that each agent received (without discounting), to get a score for each agent. This yields 2 (potentially different) scores. We then take the maximum of these 2 scores.
This yields a single score for each episode.
The environment is considered solved, when the average (over 100 episodes) of those scores is at least +0.5.
Algorithm Implementation Details:
Instantiates two separate DDPG agents and few helper methods to act and step in the enviornment. The idea behind multi-agent DDPG algorithm is to act separately in the environment and concatenate the output of both agents. After an initial action is taken in the enviornment, the states, action, reward and next action tuple is saved in the replay buffer. Note that this tuple contains the observations of both agents except for the reward which is for each spefific agent. During learning pahse, each agent individually learns from both observations available for both agents.